Los datos espaciales son fundamentales en muchas áreas, desde la geografía hasta la ciencia de datos. En R, existen varios tipos de datos espaciales que se pueden utilizar para representar información geoespacial. En este cuadernillo, exploraremos dos tipos principales de datos espaciales: puntos y polígonos.
Los datos espaciales se utilizan en una amplia gama de campos para apoyar la toma de decisiones, incluyendo medio ambiente, salud pública, ecología, agricultura, planificación urbana, economía y sociedad. Estos datos provienen de diversas fuentes y están disponibles en múltiples formatos (Moraga y Baker 2022). Por ejemplo, los datos de teledetección, como el uso del suelo y los fenómenos ambientales, se pueden obtener a través de satélites que orbitan la Tierra y otras plataformas de captura a distancia.
Las estaciones de monitoreo ubicadas en sitios específicos proporcionan información detallada sobre diversas variables ambientales y climáticas, como temperatura, precipitación y contaminación del aire. Las encuestas se emplean para recopilar datos sobre diferentes temas sociales, económicos y relacionados con la salud. Los datos espaciales también pueden derivarse del uso de teléfonos móviles y redes sociales, que pueden proporcionar información sobre la ubicación y actividades de los individuos.
Los datos espaciales pueden considerarse como el resultado de observaciones de un proceso estocástico
\[
\{Z(s) : s \in D \subset \mathbb{R}^d\}
\]
donde $D$ es un conjunto en \(\mathbb{R}^d\), \(( d = 2 )\) , y \(Z(s)\) denota el atributo que observamos en \(( s )\). Tres tipos de datos espaciales se distinguen por las características del dominio \(D\), a saber, datos de área (o enrejado), datos geoestadísticos y patrones de puntos (Cressie 1993). A continuación, describimos cada uno de los tipos de datos, y damos ejemplos de estos datos en diferentes contextos.
4.2 Datos de Área (o Enrejado)
Los datos de áreas, también conocidos como datos areales o de cuadrícula, se refieren a la información recolectada en unidades geográficas específicas, como regiones administrativas o celdas de una cuadrícula. Imagina que quieres entender cómo se distribuye una enfermedad en diferentes partes de una ciudad. En lugar de mirar cada caso individualmente, podrías sumar los casos dentro de cada barrio o distrito. Esto te permite observar patrones más amplios y entender mejor cómo ciertos factores afectan la distribución de la enfermedad.
Segun Morgan P.(2023), en los datos areales o de cuadrícula, el dominio \(D\) es una colección contable fija de unidades areales (regulares o irregulares) en las que se observan variables. Los datos areales usualmente surgen cuando el número de eventos correspondientes a alguna variable de interés se agregan en áreas. Por ejemplo, en la epidemiología espacial, las ubicaciones de individuos con una determinada enfermedad a menudo se agregan en áreas administrativas. Estos datos pueden analizarse para entender patrones geográficos e identificar factores de riesgo de la enfermedad, teniendo en cuenta la configuración del vecindario y otros factores conocidos que afectan el riesgo de enfermedad (Moraga, 2018a). Los datos areales también pueden surgir en aplicaciones de teledetección donde los satélites proporcionan información sobre varias variables, como temperatura, precipitación e índices de vegetación en celdas de una cuadrícula regular que cubre la región de estudio.
4.2.1 Ejemplo
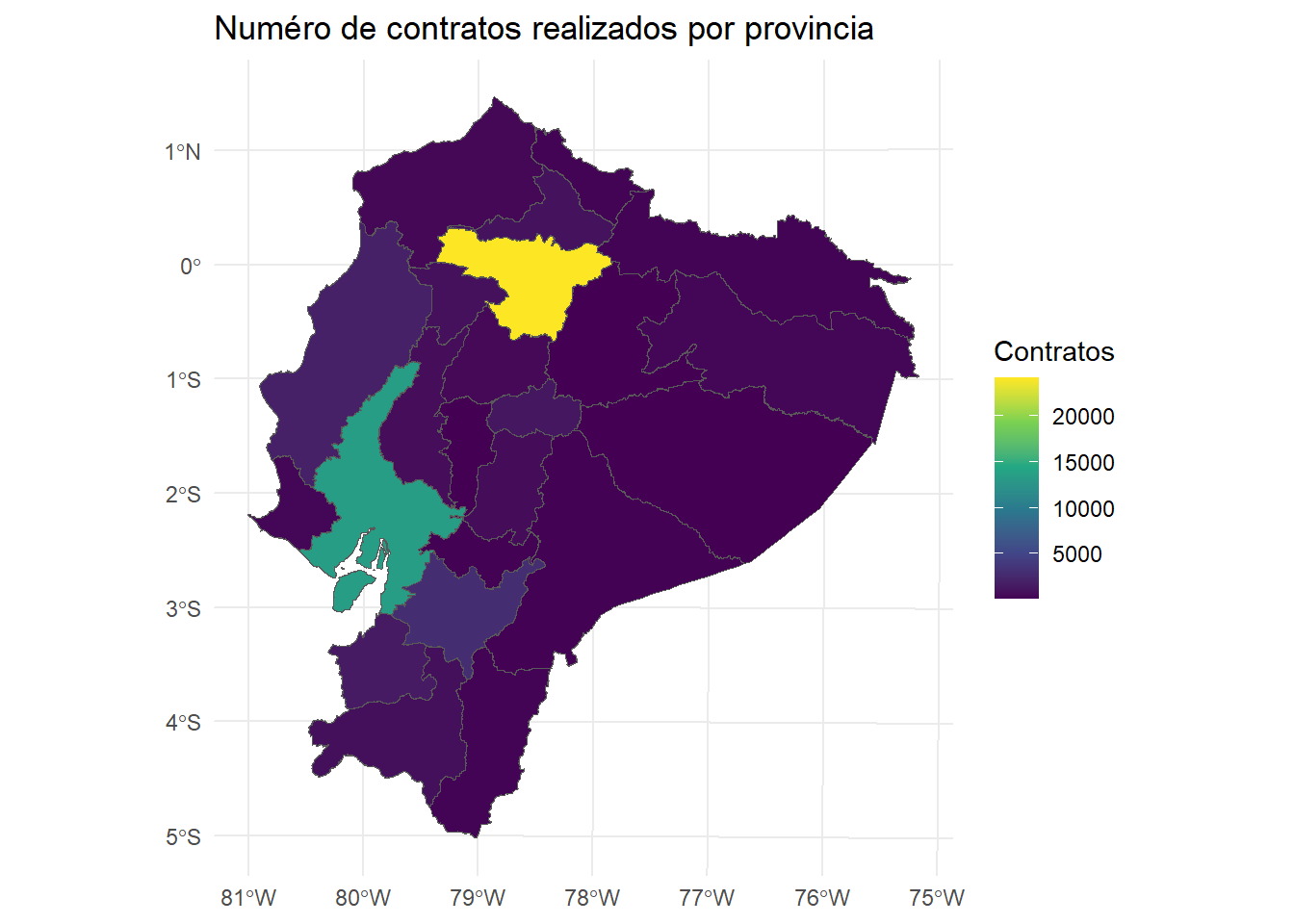
En la Figura 1 se muestra la distribución de contratos realizados por el Consejo Nacional Electoral.
Reading layer `LIMITE_PROVINCIAL_CONALI_CNE_2022' from data source
`C:\Users\alex_ergostats\Documents\geo_stats_2024_nb\LIMITE_PROVINCIAL_CONALI_CNE_2022.shp'
using driver `ESRI Shapefile'
Simple feature collection with 23 features and 3 fields
Geometry type: MULTIPOLYGON
Dimension: XY
Bounding box: xmin: 498738.4 ymin: 9445216 xmax: 1147852 ymax: 10162550
Projected CRS: WGS 84 / UTM zone 17S
#Graficamosggplot(data = ecuador_provinces) +geom_sf(aes(fill = CONTRATOS)) +scale_fill_viridis_c() +labs(title ="Numéro de contratos realizados por provincia ",fill ="Contratos") +theme_minimal()
Figura 1: Número de contratos realizados en el Ecuador por provincia.
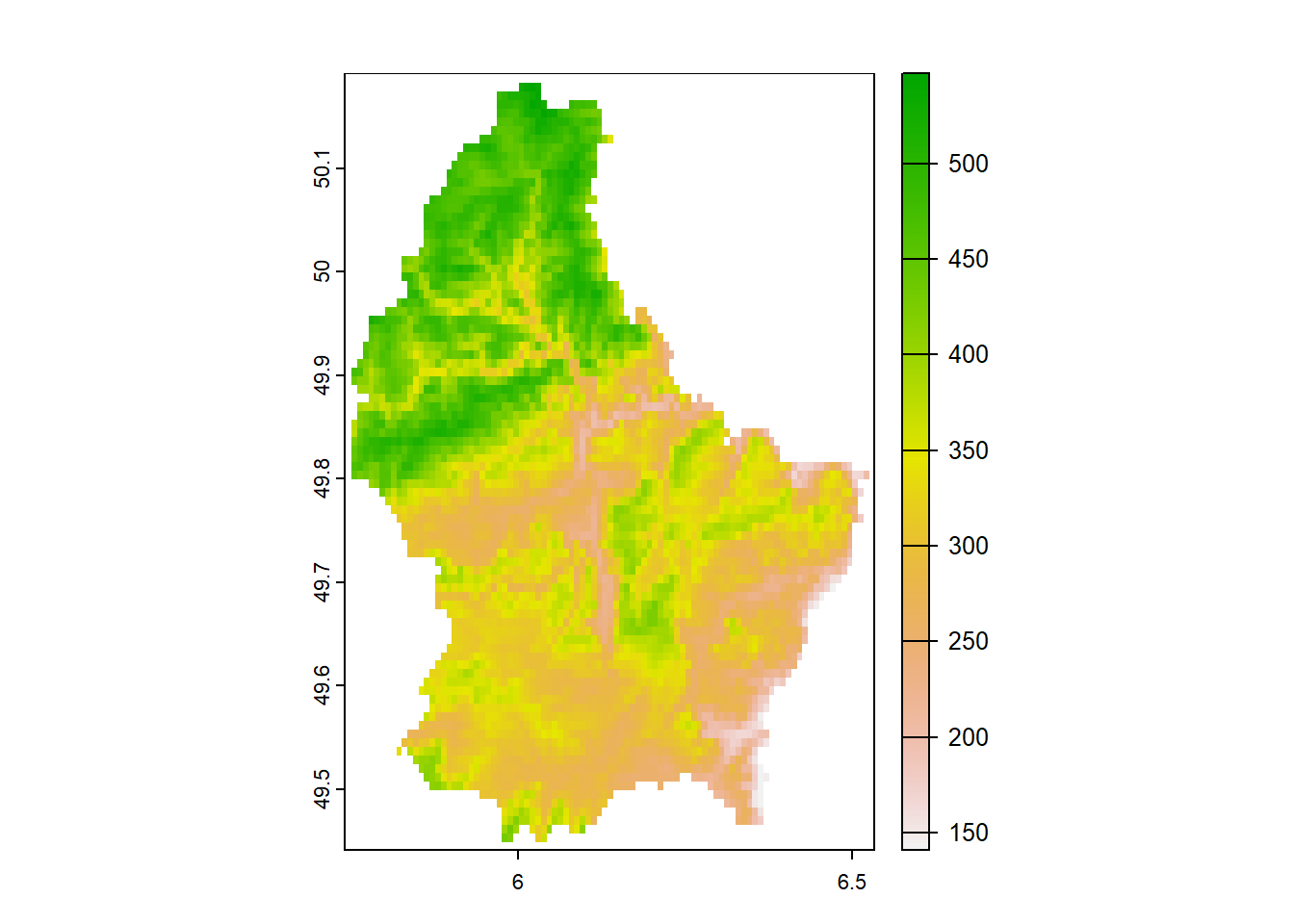
En la Figura 2 muestra la elevación de las celdas de la cuadrícula ráster que cubren Luxemburgo desde Terra ( Hijmans 2022 ) . En este caso, todas las áreas tienen el mismo tamaño que las celdas de una cuadrícula ráste
Figura 2 : Ejemplo de datos reales. Elevación en celdas de la cuadrícula de raster que cubren Luxemburgo.
4.3Datos geoestadísticos
Los datos geoestadísticos nos llevan a explorar un mundo donde la información fluye de manera continua a través del espacio. Es como si cada punto en el mapa tuviera su propia historia que contar, y nuestro desafío es tejer estas historias juntas para comprender la imagen completa. Por ejemplo, al observar la contaminación del aire, no nos limitamos a simples puntos de medición; más bien, nos sumergimos en la red interconectada de cómo la contaminación se propaga y afecta diferentes áreas.
En datos geoestadísticos, \(D\) representa un subconjunto continuo fijo del espacio euclidiano \(\mathbb{R}^d\) .El índice espacial \(s\) varía de manera continua en el espacio, lo que permite la observación de \(Z(s)\) en todas partes dentro de \(D\). Usualmente, utilizamos datos \(\{Z(s_1),\ldots,Z(s_n)\}\) observados en ubicaciones espaciales conocidas \(\{s_1,\ldots,s_n\}\) para predecir los valores de la variable de interés en ubicaciones no muestreadas. Por ejemplo, podemos utilizar mediciones de contaminación del aire en varias estaciones de monitoreo para predecir la contaminación del aire en otras ubicaciones, teniendo en cuenta la autocorrelación espacial y otros factores conocidos que predicen el resultado de interés (Cameletti et al., 2013).
4.3.1 Ejemplo
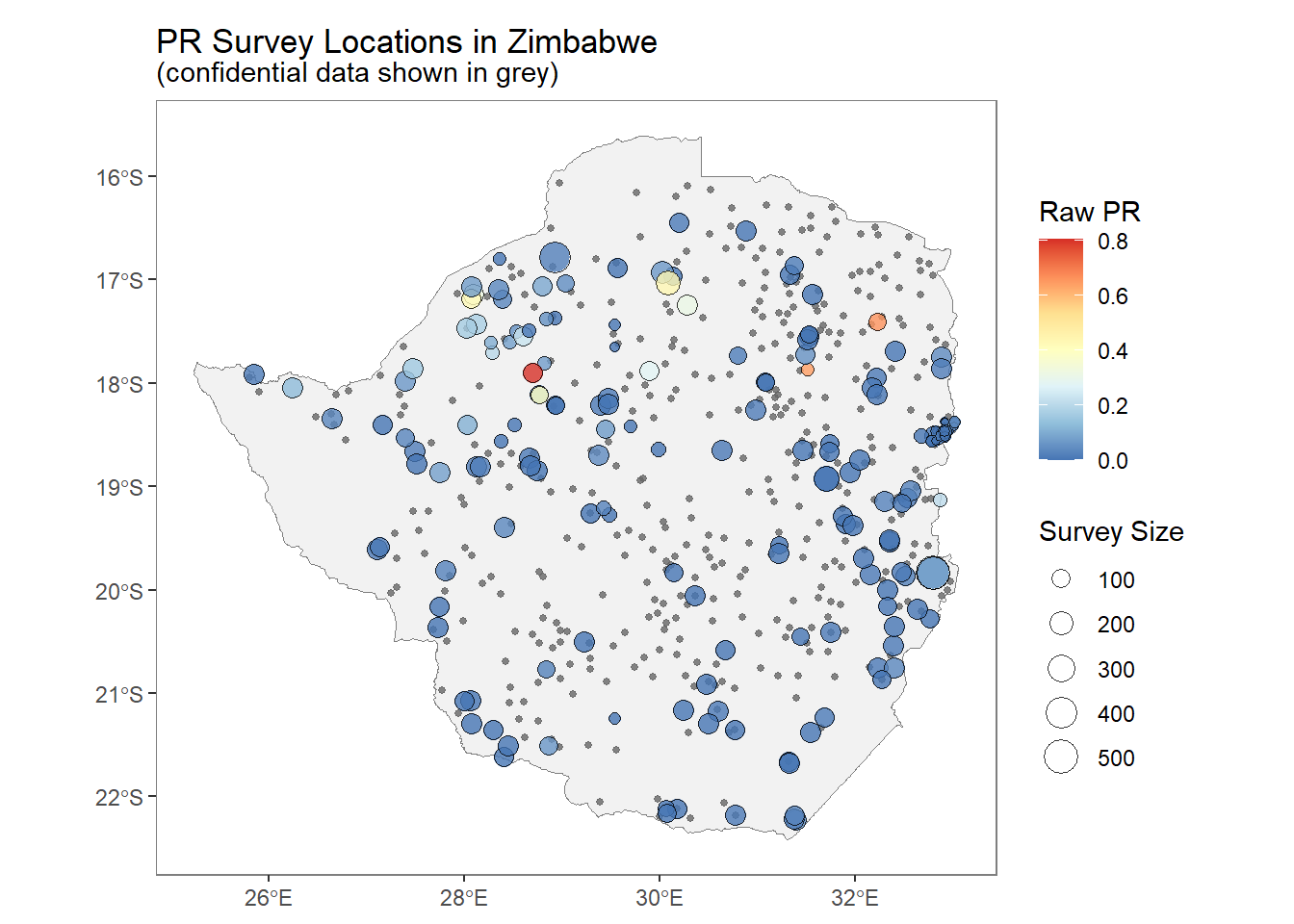
La Figura 3 muestra la prevalencia de la malaria en lugares específicos de Zimbabwe del paquete malariaAtlas (Pfeffer et al.2020). La prevalencia se calcula como el número de personas positivas a la malaria dividido por el número de personas examinadas en cada una de las ubicaciones.
library(malariaAtlas)d <-getPR(country ="Zimbabwe", species ="BOTH")ggplot2::autoplot(d)
FIGURA 3: Ejemplo de datos geoestadísticos. Prevalencia de la malaria en lugares específicos de Zimbabwe.
4.4 Patrones de Puntos
Los patrones de puntos son como esas veces que encuentras un patrón en cómo las cosas suceden en diferentes lugares. Imagina un mapa lleno de puntos, donde cada punto representa algo especial que ocurrió, como un incendio en un bosque o la ubicación de personas con una enfermedad. Observando cómo se distribuyen estos puntos en el mapa, podemos descubrir pistas sobre cómo suceden estas cosas en el espacio, como si estuviéramos resolviendo un misterio espacial.
En los patrones de puntos, el dominio \(D\) es aleatorio, lo que significa que las ubicaciones de los eventos se distribuyen de manera no uniforme en el espacio. Cada punto en el patrón indica la ocurrencia de un evento en esa ubicación específica. Por ejemplo, en la ubicación de incendios forestales, \(Z(s)\) puede ser igual a 1 \(\forall s \in D\) para indicar la presencia de un incendio en esa ubicación, o puede ser aleatorio para proporcionar información adicional sobre el evento. El análisis de patrones de puntos nos permite entender los procesos subyacentes que generan el patrón y evaluar si la distribución espacial exhibe aleatoriedad, agrupamiento o regularidad.
4.4.1 Ejemplo
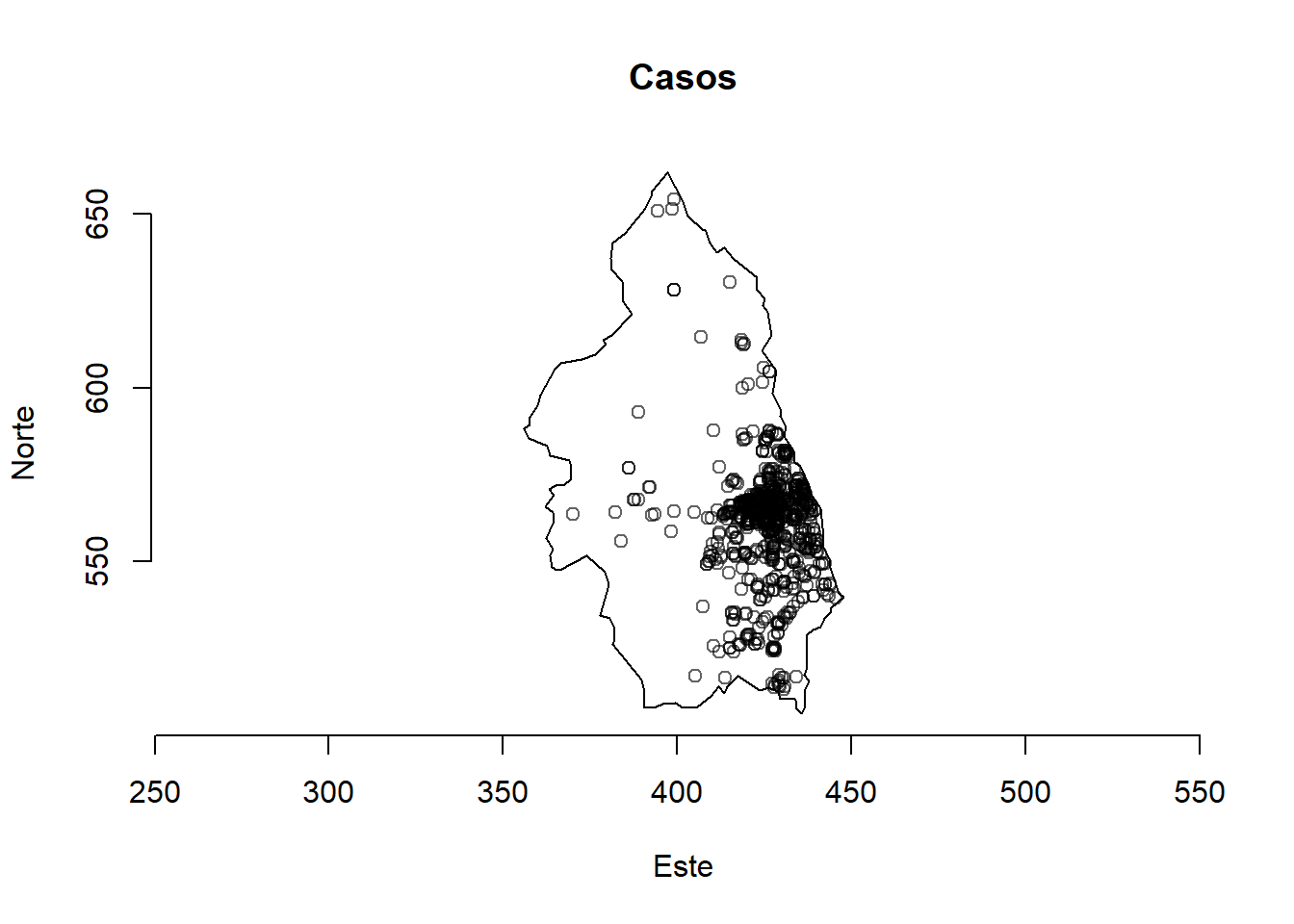
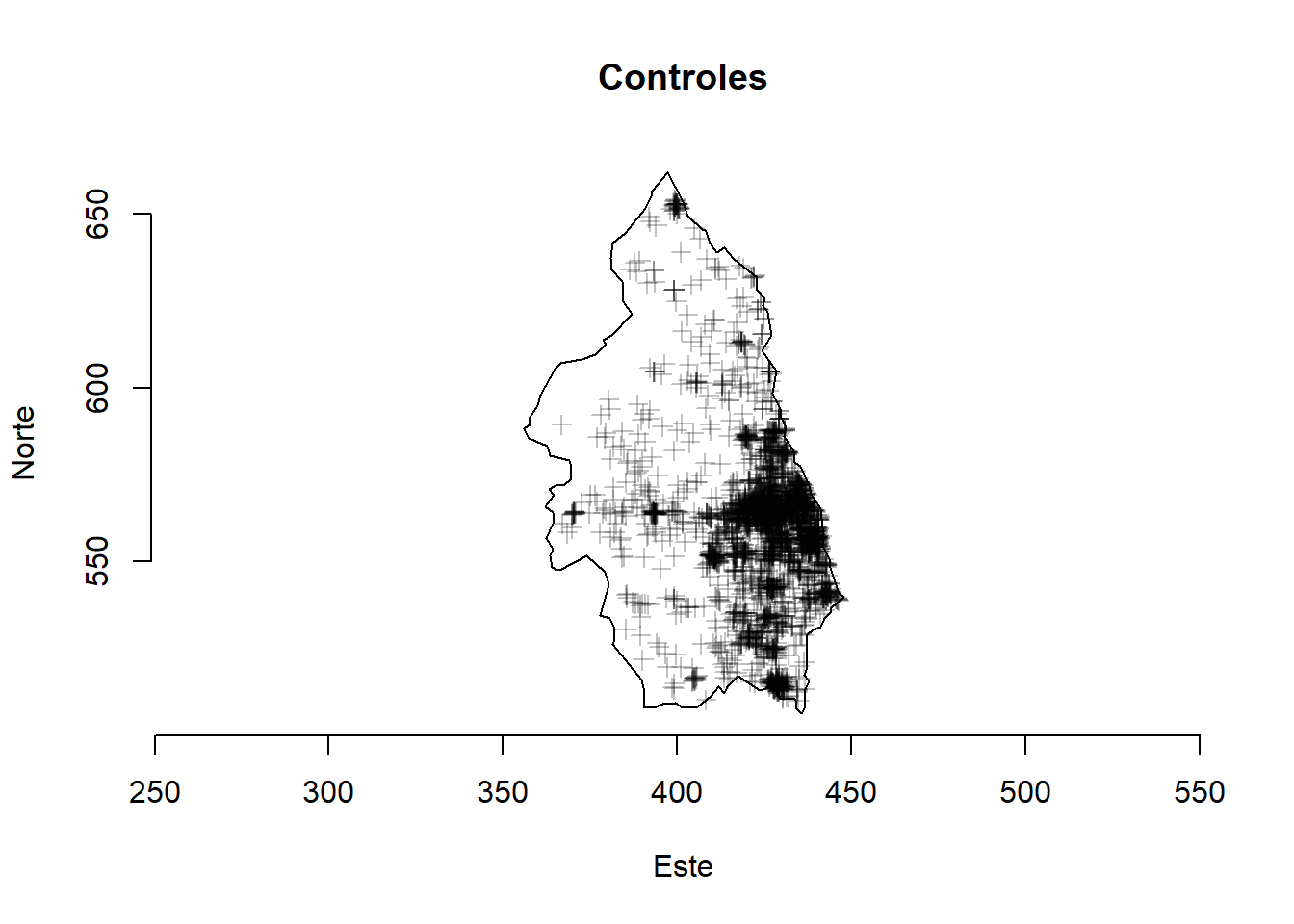
La Figura 4 muestra las ubicaciones espaciales de 761 casos de cirrosis biliar primaria y 30210 controles que representan a la población en riesgo en el noreste de Inglaterra recopilados entre 1987 y 1994. Esta información está contenida en los pbcdatos del paquete sparr (Davies y Marshall, 2023).
library(sparr)data(pbc)plot(unmark(pbc[which(pbc$marks =="case"), ]), main ="Casos")axis(1)axis(2)title(xlab ="Este", ylab ="Norte")
plot(unmark(pbc[which(pbc$marks =="control"), ]),pch =3, main ="Controles")axis(1)axis(2)title(xlab ="Este", ylab ="Norte")
Figura 4: Ejemplo de patrón de puntos. Ubicaciones de casos y controles de cirrosis biliar primaria en el noreste de Inglaterra entre 1987 y 1994
4.5Datos espacio-temporales
Los datos espacio-temporales son como un diario detallado que registra eventos tanto en el espacio como en el tiempo. Es como tener un mapa animado que muestra cómo las cosas cambian y se desarrollan a lo largo del tiempo en diferentes lugares. Por ejemplo, podemos imaginar un registro de la contaminación del aire en diferentes estaciones de monitoreo en Alemania, capturado cada hora a lo largo de un día, o un seguimiento de los terremotos que ocurren en el mundo a lo largo de los años. Estos datos nos permiten no solo comprender cómo se distribuyen los eventos en el espacio, sino también cómo evolucionan con el tiempo.
Los datos espacio-temporales surgen cuando la información está referenciada tanto espacial como temporalmente. Por lo tanto, podemos considerar los datos espaciales como agregaciones temporales o instantáneas temporales de un proceso espacio-temporal.
4.5.1 Ejemplo
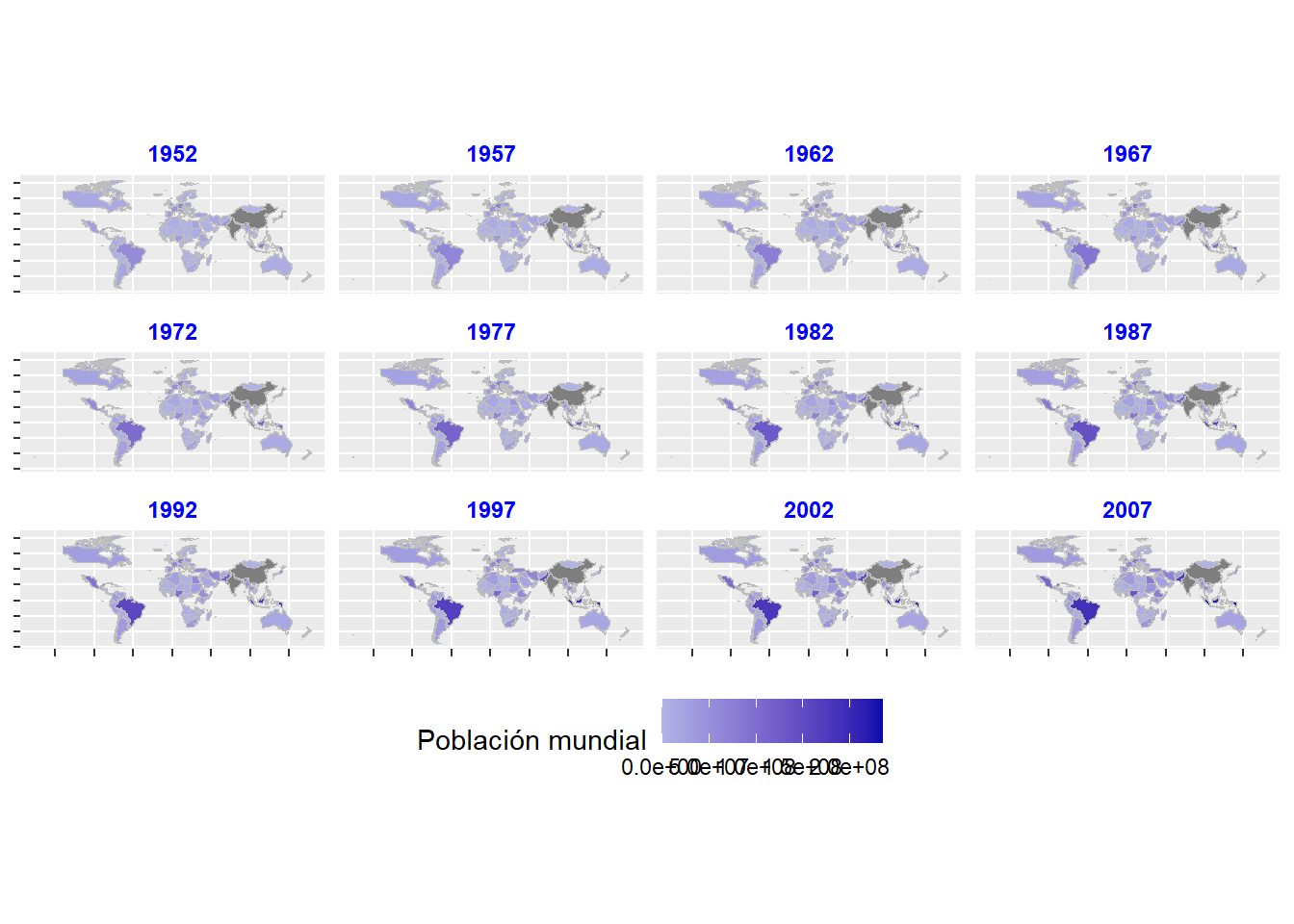
En la Figura 5 se plantea el gráfico del mundo considerando la población en cada país en los distintos años.
# A tibble: 1,704 × 6
country continent year lifeExp pop gdpPercap
<fct> <fct> <int> <dbl> <int> <dbl>
1 Afghanistan Asia 1952 28.8 8425333 779.
2 Afghanistan Asia 1957 30.3 9240934 821.
3 Afghanistan Asia 1962 32.0 10267083 853.
4 Afghanistan Asia 1967 34.0 11537966 836.
5 Afghanistan Asia 1972 36.1 13079460 740.
6 Afghanistan Asia 1977 38.4 14880372 786.
7 Afghanistan Asia 1982 39.9 12881816 978.
8 Afghanistan Asia 1987 40.8 13867957 852.
9 Afghanistan Asia 1992 41.7 16317921 649.
10 Afghanistan Asia 1997 41.8 22227415 635.
# ℹ 1,694 more rows
world <-ne_countries(scale ="medium", returnclass ="sf")world_gapminder <- gapminder %>%left_join(world, by =c("country"="admin"))
ggplot(data = world_gapminder) +geom_sf(aes(fill = pop,geometry = geometry),color ='gray',size =0.3 ) +guides(fill =guide_colorbar(title ="Población mundial")) +scale_fill_gradient(limits =c(0, 235520226),high ="#010BAD",low ="#B1B3E6",guide ="colorbar" ) +facet_wrap(. ~ year) +theme(axis.text =element_blank(),strip.text =element_text(size =10)) +# labs(title = "Inversión en TICs por Año, por Provincia y por Sector") +theme(legend.position ="bottom",strip.text =element_text(face ='bold',size =9,color ='blue' ),strip.background =element_rect(fill ='white') )
Figura 5 Población mundial 1952- 2007
Fíjate como el territorio de Rusia aparece siempre gris. En el ejemplo que presentamos ocupamos dos fuente de datos distintas, las cuales antes deben ser procesadas para poderlas integrar y que nuestro mapa mejore sustancialmente. Para este último objetivo ocuparemos tidyverse y sus funciones.
4.6 Datos de Movilidad
Los datos de movilidad son como ríos invisibles que conectan diferentes lugares, mostrándonos cómo las personas y otras entidades se desplazan de un lugar a otro. Es como observar el flujo de personas en una ciudad, viendo cómo se mueven de un vecindario a otro, o seguir el movimiento de vehículos en una red de carreteras. Estos datos nos ayudan a comprender cómo interactúan los lugares y cómo se propagan fenómenos como enfermedades o información a través de estas redes invisibles.
Además de los tres tipos clásicos de datos espaciales (es decir, datos areales, geoestadísticos y de patrones de puntos), también podemos considerar otros datos espaciales como flujos que contienen el número de individuos u otros elementos que se mueven entre ubicaciones. Aquí, vemos un ejemplo de datos de flujos del paquete epiflows. Este paquete nos permite predecir y visualizar la propagación de enfermedades infecciosas basadas en flujos entre ubicaciones geográficas. El paquete contiene datos de Brazil_epiflows con el número de viajeros entre estados brasileños y otras ubicaciones. Podemos utilizar estos datos para crear un objeto epiflows que nos permita utilizar las funciones de predicción y visualización. Luego, podemos visualizar los flujos de población con vis_epiflows utilizando una red dinámica, y map_epiflows utilizando un mapa interactivo.
Comprender los distintos tipos de datos espaciales es fundamental en una variedad de campos científicos y aplicados. Desde la salud pública hasta la gestión ambiental y la planificación urbana, los datos espaciales nos proporcionan una visión profunda sobre cómo los fenómenos se distribuyen y evolucionan en el espacio y el tiempo. Con herramientas adecuadas, podemos analizar patrones complejos, prever cambios futuros y tomar decisiones informadas que mejoren nuestra calidad de vida y la sostenibilidad de nuestro entorno. La capacidad de interpretar y utilizar estos datos no solo enriquece nuestra comprensión del mundo, sino que también nos permite responder de manera más efectiva a desafíos globales como la propagación de enfermedades, el cambio climático y la urbanización acelerada.