Análisis de grandes volumenes de información con R
Author
Alex Bajaña
Published
8/18/23
Durante los últimos tres meses, he trabajado en una serie de transferencias de conocimientos con los colegas del Servicio de Rentas Internas (SRI) una de las instituciones en las que inicie mi carrera laboral. El objetivo que nos planteamos con el SRI fue dotar a los funcionarios de conocimientos introductorios de programación en R aplicada a tres temas específicos: análisis de series de tiempo, manejo y análisis de encuestas, y por último, el manejo de grandes volúmenes de información con Spark.
La presentación de este último tema se me hizo un desafío ya que el framework de Apache Spark posee particularidades que deben ser recorridas para poder realizar nuestro análisis. Por ello he decidido cambiar un poco el formato con el que estuve trabajando en estas transferencias de conocimientos y opte por este documento en el cual pretendo explicar con detenimiento el ejercicio que realizamos con los colegas del SRI en relación al análisis de Big Data con Spark.
Durante la transferencia de conocimientos empleamos un conjunto de datos que colecciona los precios de productos electronicos ofertados en paginas web. Entonces, nuestro objetivo fue determinar categorías de productos basados en su descripción, precio y detalles de su venta. Con estás categorías será más fácil determinar rangos de precios entre productos de una misma categoría y así evaluar indicadores como inflación o evaluar escenarios donde se gravan con impuestos a estos productos.
En este documento, primero vamos a recorrer algunos puntos importantes sobre Apache Spark. Luego, hablaremos sobre nuestro conjunto de datos y la limpieza preliminar de este. A continuación vamos a realizar el proceso de feature engineering dentro de una pipe-line como una pipe-line de Spark que culmina con un modelo de K-means para realizar los clusters de productos electrónicos. Finalmente evaluaremos los resultados de esa pipe-line y daré algunas recomendaciones para otras implementaciones de modelos.
¿Qué es y cómo funciona Apache Spark?
Apache Spark es un framework (marco conceptual) de procesamiento de datos distribuido que permite analizar grandes cantidades de datos de manera rápida y eficiente. Funciona dividiendo los datos en partes más pequeñas que se pueden procesar en paralelo en un clúster de máquinas.
Sparklyr es una librería de R que facilita el uso de Spark para el análisis de datos. Te permite escribir código R para interactuar con Spark y ejecutar tareas de análisis en grandes conjuntos de datos.
Para entender cómo funciona Spark para Big Data Analysis, es importante comprender los siguientes conceptos:
Datasets: Los datasets son los conjuntos de datos que se van a analizar. Spark puede trabajar con una variedad de tipos de datasets, incluyendo archivos de texto, archivos CSV, bases de datos y tablas de Hive.
Clúster: Un clúster es un grupo de máquinas que se utilizan para procesar datos con Spark. El número de máquinas en un clúster determina la cantidad de datos que Spark puede procesar a la vez.
RDDs: Los RDDs (Resilient Distributed Datasets) son la estructura de datos básica de Spark. Los RDDs son conjuntos de datos distribuidos que se pueden procesar de manera paralela en un clúster.
Cuando trabajas con Sparklyr, puedes usar R para interactuar con Spark y realizar tareas de análisis en tus datasets. Por ejemplo, puedes usar R para cargar datos de un archivo de texto, aplicar operaciones de limpieza y transformación a los datos, y luego ejecutar análisis estadísticos o de aprendizaje automático.
Si no tengo un clúster ¿Cómo puedo usar Apache Spark?
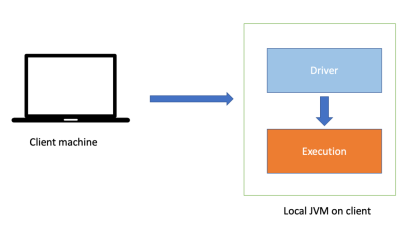
Apache Spark también ofrece una alternativa local para poder trabajar en un computador individual. La principal diferencia entre usar Sparklyr en local y en un clúster es que, en local, todos los procesos de Spark se ejecutan en una sola máquina, mientras que en un clúster, los procesos se dividen entre varias máquinas. Esto tiene un impacto significativo en el rendimiento y la escalabilidad.
En local, Sparklyr utiliza el procesador y la memoria de la máquina local para procesar los datos. Esto significa que el rendimiento está limitado por la potencia de la máquina local. Además, si los datos son demasiado grandes para caber en la memoria de la máquina local, Sparklyr tendrá que escribirlos en el disco, lo que puede reducir el rendimiento.
En un clúster, Sparklyr utiliza los procesadores y la memoria de todas las máquinas del clúster para procesar los datos. Esto significa que el rendimiento puede ser mucho mayor que en local, incluso para conjuntos de datos muy grandes. Además, como los datos no tienen que caber en la memoria de una sola máquina, Sparklyr puede procesarlos de manera más eficiente.
Spark desplegado de manera local
En términos de escalabilidad, Sparklyr en local solo puede procesar conjuntos de datos que caben en la memoria de la máquina local. Si los datos son demasiado grandes, Sparklyr no podrá procesarlos. Por otro lado, Sparklyr en un clúster puede procesar conjuntos de datos de cualquier tamaño, ya que los datos se pueden distribuir entre varias máquinas.
Spark desplegado en modo cluster
Sparklyr en local es una buena opción para aprender a usar Spark y realizar análisis de datos pequeños. Sin embargo, para conjuntos de datos grandes o complejos, Sparklyr en un clúster es la mejor opción.
Aquí hay algunos consejos para elegir entre Sparklyr en local y en un clúster:
Tamaño del conjunto de datos: Si el conjunto de datos es pequeño, Sparklyr en local puede ser una buena opción. Sin embargo, si el conjunto de datos es grande, Sparklyr en un clúster es la mejor opción.
Complejidad del análisis: Si el análisis es simple, Sparklyr en local puede ser suficiente. Sin embargo, si el análisis es complejo, Sparklyr en un clúster puede proporcionar un mejor rendimiento y escalabilidad.
Recursos disponibles: Si no tienes acceso a un clúster, Sparklyr en local es la única opción. Sin embargo, si tienes acceso a un clúster, Sparklyr en un clúster puede proporcionar un mejor rendimiento y escalabilidad.
Nuestros datos
La base de datos “e-product-pricing” de Kaggle contiene datos de precios de productos de comercio electrónico de diferentes categorías, como electrónica, ropa, muebles, etc. Los datos se recopilaron de varias fuentes, incluidas tiendas en línea, reseñas de productos y sitios web de comparación de precios.
La base de datos contiene las siguientes columnas:
product_name: El nombre del producto.
product_category: La categoría del producto.
product_brand: La marca del producto.
product_price: El precio del producto.
product_rating: La calificación del producto.
product_review_count: El número de reseñas del producto.
product_url: La URL del producto.
Los datos se pueden utilizar para una variedad de propósitos, como:
Análisis de precios: Para comprender cómo los precios de los productos varían según la categoría, la marca y otros factores.
Análisis de tendencias: Para identificar tendencias en los precios de los productos a lo largo del tiempo.
Análisis de la competencia: Para comparar los precios de los productos de diferentes vendedores.
La página de Kaggle suele pedir crear una cuenta (si no la tenemos) para poder descargar los datos. Sin embargo el proceso es sencillo y se realiza en minutos.
Indicaciones preliminares
Siempre recomiendo trabajar con proyectos de R, ya que facilitan el manejo de archivos y rutas para mantener el código y las bases de datos ordenados. Entonces el primer paso que recomiendo es crear un proyecto (Files > New Project) o trabajar dentro de uno.
Dentro del proyecto creamos dos directorios:
data/ donde vamos a guardar nuestros achivos de datos. Aqui guardamos el archovo descargado de Kaggle.
script/ donde vamos a guardar los scripts de R para nuestro analisis.
Instalamos las librerías de R de acuerdo con la guía de instalación si no las tenemos (Guía de instalación)
En este documento vamos a recorrer el archivo script_sparklyr_electronics.R que lo pueden descargar en este enlace (click aquí), el código explicado a continuación es exactamente igual en contenido al archivo en mención.
Manos a la obra
Primero, siempre vemos la versión de R con la vamos a trabajar:
R.version
_
platform x86_64-w64-mingw32
arch x86_64
os mingw32
crt ucrt
system x86_64, mingw32
status
major 4
minor 3.1
year 2023
month 06
day 16
svn rev 84548
language R
version.string R version 4.3.1 (2023-06-16 ucrt)
nickname Beagle Scouts
Si no tenemos instalada ninguna versión nos devolvera el valor NULL lo que significa que deberemos instalar al menos una. Para ver las versiones disponibles empleamos:
Para el ejercicio vamos a instalar la versión 3.3.2, la cual viene con una instalación de Hadoop por default. Esta es la versión que empleamos en la transferencia de conocimientos.
spark_install("3.3.2")
Genial, con esto ya tenemos todos los requisitos para empezar nuestro trabajo con Spark. Para poder dar inicio a nuestro análisis debemos crear una conexión de Spark. Lo hacemos con la función spark_connect() indicando que vamos a trabajar de manera local y con la versión de Spark que tenemos instalada.
Con esta conexión, el entorno de Rstudio nos ofrece una ventana interactiva llamada Conections para monitorear el comportamiento de nuestro entorno de Spark mientras trabajamos con R.
Lectura de los datos
Para poder trabajar con nuestros datos desde un archivo, usualmente usamos las funciones de la librería readr, lo cual nos devuelve un data.frame en el entorno de R . Sin embargo, para poder trabajar de manera distribuida debemos cargar nuestra base de datos como una tabla de Spark. Para ello empleamos la función spark_read_csv() indicando que vamos a almacenar está tabla en el entorno de Spark al cual hacemos referencia con el objeto conn.
#|echo: true#|eval: falseelectronics <-spark_read_csv(sc = conn, name ="electronics",path ="data/ElectronicsProductsPricingData.csv")
La función show() nos mostrará la cabecera de la tabla, mientras que tbl_vars() nos muestra los nombres de las columnas en nuestra tabla.
# Preview de las 100 primeras lineas de la tablashow(electronics)
# Obtengo los nombres de las variables:tbl_vars(electronics)
Vamos a seleccionar variables relevantes para nuestro análisis. Es importante señalar que determinadas funciones de la libreria dplyr dentro del tidyverse son compatibles con tablas de Spark. Sin embargo, en los casos en que una función no este disponible para las tablas de Spark, tenemos funciones de Hive para poder hacer nuestros análisis. Por ejemplo en la selección de variables podemos usar la función select() para la operación de seleccionar variables.
Error: org.apache.spark.sql.AnalysisException: Undefined function: top_n_rank. This function is neither a built-in/temporary function, nor a persistent function that is qualified as spark_catalog.default.top_n_rank.
Un caso similar pasa con la funcion separate() la cual toma una columna de un data.frame para crear nuevas variables a partir de separar un texto empleando un delimitador. Para tablas de Spark empleamos la siguiente sintaxis:
La función ft_regex_tokenizer() va a crear un array (o arreglo de datos en español) con los textos separados por un espaciodentro de una columna de la tabla de Spark. Luego con sdf_separate_column() distribuimos estos textos en dos columnas: una para el valor numérico del peso y otra para la unidad de medida.
Vamos a ver cuantas unidades de medida existen en la base de datos con el fin de llevar toda la información del peso a una sola unidad de medida, en este caso vamos a usar libras. Adicional a ello vamos a llevar nuestro resumen al ambiente de R para trabajarla de manera más sencilla, esto se realiza con la función collect().
# Este conteo sigue siendo una tabla de Spark:unidades <- electronics %>%count(weight_unit)# Con collect() la llevo a R:unidades <- unidades %>%collect()print(unidades)
# A tibble: 10 × 2
weight_unit n
<chr> <dbl>
1 ounces 1377
2 pounds 3083
3 lb 1528
4 <NA> 47
5 lbs 311
6 oz 819
7 kg 38
8 g 38
9 lb. 7
10 fiberboard 1
Armamos una tabla de equivalencias para las unidades de medida con un factor de equivalencia a libras:
Un momento, esto nos da error. Es importante señalar, que para operar con varias tablas, estas deben ser tablas de Spark, por ello el error. Entonces para poder unir nuestras tablas primero debemos subir nuestra tabla de equivalencias a Spark con la función copy_to().
Y procedemos a la unión de tablas y la homologación de los pesos a libras:
electronics <- electronics %>%# Unión de las tablasinner_join(unidades_peso) %>%# Homologación de unidades de peso:mutate(weight_value =as.numeric(weight_value),weight_value_hom = weight_value*factor ) %>%# Sacamos las variables temporales:select(-n,-factor,-weight_value,-weight_unit)
Joining with `by = join_by(weight_unit)`
En la base de datos se tienen tres variables de precios. El primero es el precio de entrega (shipping en inglés), luego tenemos los precios máximos y mínimos del producto. Estos precios en la base de datos pueden estar en dólares americanos (USD) y dólares canadienses (CAD), por lo cual aplicamos un tratamiento similar que nos lleve estos precios a una única unidad, en este caso dólares americanos (USD.)
# Mismo tratamiento para el precio de entrega:# Considerando que hay dólares y dólares canadienses:precios_envio <- electronics %>%count(prices_shipping) %>%collect()# Tratamiento para los precios de envio:precios_envio <- precios_envio %>%mutate(prices_shipping_sep = prices_shipping) %>%separate(prices_shipping_sep,sep =" ",into =c("unit_shipping","price_shipping"))
# Transformamos todo a dolar:precios_envio <- precios_envio %>%mutate(factor_shipping =case_when( unit_shipping =="USD"~1, unit_shipping =="CAD"~0.78,str_detect(prices_shipping,"[Ff]ree") ~0,TRUE~NA_real_),price_shipping_dolar =as.numeric(price_shipping),price_shipping_dolar = price_shipping_dolar*factor_shipping, ) %>%select(prices_shipping,price_shipping_dolar)
Warning: There was 1 warning in `mutate()`.
ℹ In argument: `price_shipping_dolar = as.numeric(price_shipping)`.
Caused by warning:
! NAs introducidos por coerción
precios_envio <-copy_to(dest = conn,df = precios_envio,name ="precios_envio",overwrite = T)# Unimos a la base:electronics <- electronics %>%inner_join(precios_envio) %>%select(-prices_shipping)
Joining with `by = join_by(prices_shipping)`
# Hacemos la misma transformación a la unidad de precio:electronics %>%count(prices_currency)
# Source: spark<?> [?? x 2]
prices_currency n
<chr> <dbl>
1 " 3 ft. 8 GA Black Ground Cable" 1
2 "USD" 4247
3 "CAD" 1
El último paso antes de pasar a modelar nuestros datos con Spark es limpiar las categorías de la variable price condtion la cual nos indica si el producto es nuevo, usado o repuesto por la empresa vendedora o la empresa que manufacturo el producto.
# Verificamos la condición del precio:electronics %>%distinct(prices_condition)
# Source: spark<?> [?? x 1]
prices_condition
<chr>
1 "\"5/16\"\" Ring Terminal"
2 "Manufacturer refurbished"
3 "New"
4 "New other (see details)"
5 "Seller refurbished"
6 "Used"
# Extraemos las condiciones del precio:electronics <- electronics %>%mutate(prices_condition =str_to_lower(prices_condition),prices_condition_new =regexp_extract(prices_condition, "(new|used|refurbished)"),prices_condition_new =if_else(prices_condition_new =="",NA_character_, prices_condition_new)) %>%select(-prices_condition)# Verificamos:electronics %>%distinct(prices_condition_new)
# Source: spark<?> [?? x 1]
prices_condition_new
<chr>
1 NA
2 new
3 refurbished
4 used
Hemos hecho la limpieza de nuestra base de datos. Ahora vamos a usar Spark para cumplir con el objetivo de nuestro análisis.
La pipe-line de sparklyr
Una pipe-line de sparklyr es una secuencia de pasos que se utilizan para procesar datos con Spark. Las pipe-lines son una forma poderosa de organizar y automatizar el análisis de datos.
La pipe-line de sparklyr que vamos a construir consta de los siguientes pasos:
Aplicar transformaciones: Una vez que los datos estén limpios y convertidos, se pueden aplicar transformaciones para modificar los datos de acuerdo con los requisitos del análisis. Las transformaciones pueden incluir operaciones matemáticas, estadísticas y de aprendizaje automático.
Analizar los datos: Una vez que los datos hayan sido transformados, se pueden analizar para responder a preguntas de investigación. Los análisis pueden incluir visualización de datos, análisis estadísticos y aprendizaje automático.
Pensemos en las pipe-lines como recetas de cocina que podemos reproducir cada que queramos un platillo exquisito siempre que empleemos los mismos ingredientes en el mismo orden. Entonces nuestra receta o pipe-line va a empezar con la función ml_pipeline() la cual va crearse considerando al conexión a Spark a la que hace referencia el objeto conn.
pipe_line <-ml_pipeline(conn)
Ahora vamos a agregar algunos pasos a nuestra receta. Vamos a ir por parte como cuando hacemos una receta de cocina. La preparación de variables (feature engineering) para nuestra pipe-line la vamos a realizar con las funciones ft_*de la librería sparklyr.
Primero vamos a tratar las variables numéricas. En ese sentido, los dos tratamientos que vamos a realizar hacen referencia a: cómo tratar los valores vacíos y cómo vamos a trabajar las diferencias en escalas de estas variables. En primer lugar, imputamos todas las variables con el valor de su mediana:
Las funciones ft_* por lo general piden una columna de input y otra columna de output para poder conservar la variable original antes de la transformación. En el caso de ft_imputer() podemos declarar más de una columna a la vez. Sin embargo esta función nos devuelve un array por lo que antes de continuar con la pipe-line vamos a transformar los resultados a vectores con los cuales seguir operando en pasos posteriores con ft_vector_assembler().
A continuación vamos a llevar a las variables numéricas a una misma escala, para ello centramos los datos (retamos la media aritmetica de la variable) y escalamos (dividimos para la desviación estandar). En lugar de hacerlo a mano, empleamos ft_standard_scaler(). Este paso se debe hacer para cada variable numérica que es resultado del paso anterior:
Las variables de texto como son prices_merchant, name, manufacturer, brandycategories son cadenas de texto, de considerable extensión en algunos casos, que inicialmente no están listas para ser empleadas en el análisis. Por ello será necesario emplear las siguientes funciones:
La primera función, ft_tokenizer(), tokeniza el texto en el campo name y lo coloca en un nuevo campo llamado name_t. Un tokenizador es una función que divide el texto en unidades más pequeñas, como palabras, frases o caracteres.
La segunda función, ft_stop_words_remover(), elimina las palabras de parada del texto tokenizado. Las palabras de parada son palabras comunes que no aportan información significativa al análisis, como “el”, “la”, “y”.
La tercera función, ft_count_vectorizer(), vectoriza el texto tokenizado sin las palabras de parada. La vectorización es el proceso de convertir texto en una representación numérica que puede ser utilizada por algoritmos de aprendizaje automático. En este caso, se utiliza un vectorizador de recuento, que crea un vector para cada palabra que aparece en el texto. El valor del vector es el número de veces que aparece la palabra en el texto.
Estás operaciones las pasamos por cada variable de texto:
Los parámetros min_df y binary controlan la forma en que se crea el vector. El parámetro min_df especifica el número mínimo de veces que una palabra debe aparecer en el texto para que se incluya en el vector. El parámetro binary especifica si el vector debe ser binario, lo que significa que solo tendrá valores 0 o 1.
Para terminar esta fase de construcción de la pipe-line vamos a contruir un vector de variables transformadas (features) que va a ser el insumo para nuestro modelo de K-means().
Excelente! Ya tenemos nuestra receta lista. Debemos tener en cuenta dos cosas:
La pipe-line es simplemente una receta, almacena los pasos que van a recorrer los datos de nuestra tabla de Spark desde la construcción de variables hasta el modelado. Si imprimimos el objeto pipe-line vamos a ver estos pasos.
Aun no hemos empleado nuestros datos en la pipe-line. Primero debemos entrar nuestro modelo, luego lo evaluamos y finalmente lo aplicamos.
Vamos a ver como generar nuestro modelo con los datos en el objeto electronics.
¿Y el modelo?
Es hora de ver los resultados de todo este análisis. Primero vamos a crear dos sets, uno de entrenamiento (70% aleatorio de la tabla) y otro de prueba (30% restante).
Si miramos el objeto modelo vamos a ver los mismos pasos que en la pipe-line. Sin embargo si prestas atención a los parámetros de ft_standard_scaler() vamos a ver que los valores de la media y desviación estandard han sido calculados. Y en la siguiente vez que apliquemos esta pipeline a otro set de datos distinto se van a aplicar estos parámetros calculados en el entrenamiento.
Evaluamos el modelo de clustering con los datos de entrenamiento. En este punto es necesario revisar algunos criterios para obtener un número adecuado de clusters, los cuales no los discutiremos en este documetno. Sin embargo se fijo en 10 el valor.
Verificamos la calidad de nuestros clusters de acuerdo a la info de la base de datos. Para este paso vamos a separar los textos de la variable categories para extraer las palabras más frecuentes en las descripciones de los productos. El objetivo es determinar si en cada cluster resultante están presentes productos que comparten características similares.
all_words <- prediction %>%# Separamos los textos de acuerdo a cualquier simbolo:mutate(categories =regexp_replace(categories, "[_\"\'():;,.!?\\-]", " ")) %>%ft_tokenizer(input_col ="categories",output_col ="word_list" ) %>%# Removemos las palabras de alto:ft_stop_words_remover(input_col ="word_list",output_col ="wo_stop_words" ) %>%# Extramos las palabras en una columna wordsmutate(word =explode(wo_stop_words)) %>%filter(nchar(word) >2)# Contamos la frecuencia de las palabras separadas en las categorias de los productos en cada cluster:counte <- all_words %>%count(word,cluster) %>%collect() counte %>%group_by(cluster) %>%top_n(5) %>%arrange(cluster,n)
Selecting by n
# A tibble: 60 × 3
# Groups: cluster [10]
word cluster n
<chr> <int> <dbl>
1 led 0 277
2 electronics 0 400
3 home 0 403
4 video 0 620
5 tvs 0 1747
6 bluetooth 1 390
7 home 1 486
8 portable 1 532
9 audio 1 884
10 speakers 1 1063
# ℹ 50 more rows
Nada mal, vemos que en el cluster 0 están productos que involucran productos electronicos para el hogar. En el cluster 1, en cambio vemos productos como DVD, y discos de blue ray. Si bien este ejercicio no es perfecto, vamos por buen camino.
Excelente hemos aplicado nuestra pipe-line a nuestros dos conjuntos de datos.
Recapitulación y palabras finales
En este documento antes que ser el desarrollo de un modelo de machine learning completo y profundo, es una guía para la implementación de uno de estos modelos empleando la librería sparklyr de R. Quiero resumir los pasos recorridos una vez más:
Hablamos sobre las particularidades de Spark
Configuramos Spark para poder trabajar con R.
Cargamos nuestra base de datos en Spark para manipularla y limpiar sus columnas.
Construimos una pipe-line con sparklyr para tratar:
Variables numéricas
Variables de texto
Un modelo de K-means
Creamos conjuntos de tratamiento y prueba
Contrastamos brevemente los resultados de nuestra pipe-line
Estos pasos no están escritos en piedra pero puede ser una guía para empezar con los conceptos básicos del procesamiento de datos de gran volumen con Spark.
Quiero finalizar este documento con un agradecimiento a María Leonor Oviedo y a Nestor Villacreses, amigos y colegas, por la ayuda en la ejecución de las transferencias de conocimientos en el SRI.